This guide gives you: ✅ A 30-day realistic strategy ✅ Architecture-level discussions ✅ Interview stories that actually happened ✅ Cheat sheets & mind map prompts ✅ Edge cases you can’t afford to miss
Week 1: Polish the Fundamentals — But Speak Like a Senior
I didn’t waste time re-reading Java basics. I reframed them from an architectural and memory-management perspective.
What I Focused On
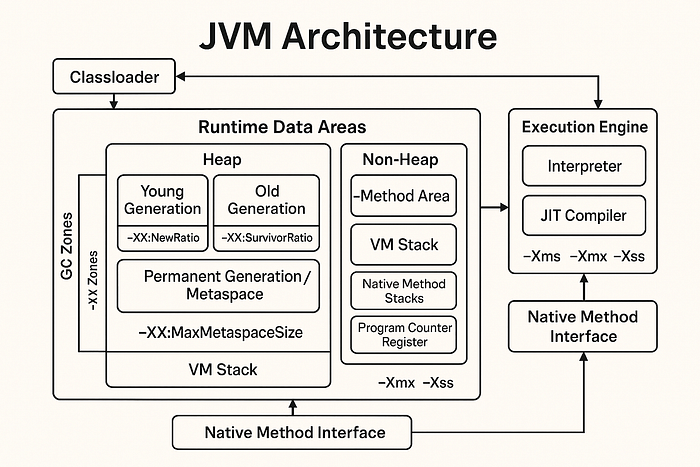
✅ Memory Management and JVM Tuning
- Heap vs Stack — not just definitions, but when to increase which in real workloads.
- GC algorithms — CMS vs G1 vs ZGC.
- Capgemini asked: “Which GC would you prefer for a latency-sensitive trading system?”
My response:
“For a latency-sensitive trading platform — especially one where predictability is critical, like order matching or real-time quotes — I’d lean towards the Z Garbage Collector (ZGC) or Shenandoah if we’re on a newer JVM version that supports them.
Here’s my reasoning:
- Low pause times are non-negotiablein trading systems. Even 100ms GC pauses can delay critical transactions. Traditional collectors like Parallel GC or even CMSintroduce noticeable stop-the-world pauses as the heap grows.
- ZGC and Shenandoah are designed for low-latency workloads. They both offer pause times in the sub-millisecond range, even with large heaps (multi-gigabyte). They achieve this by doing concurrent compaction and using region-based memory management.
- Between ZGC and Shenandoah, I usually recommend ZGC for newer JVM versions (Java 17+) because:
- It scales better with larger heaps
- It has better integration with native memory tracking
- We’ve tested it in our previous high-throughput pricing engine and saw GC pause times drop from 200ms (with G1GC) to consistently under 5ms
I also emphasized that GC selection isn’t just about theoretical performance. It needs to be:
- Benchmarked against realistic production loads
- Tuned with the right flags (
-XX:+UseZGC,-Xms,-Xmx,-XX:MaxHeapFreeRatio, etc.) - Monitored over time with real latency metrics using tools like JFR, Prometheus, or Grafana dashboards
Lastly, I added that garbage collector alone isn’t enough — we also need to:
- Minimize object allocation, especially in tight trading loops
- Prefer off-heap storage (e.g., Chronicle Queue) for ultra-low-latency messaging
- Use thread-local objects and object pooling where appropriate
That answer led to a follow-up discussion on GC tuning in microservices vs monoliths, which I navigated using real stories from past systems I worked on.”
✅ Java Concurrency (Deep Dive)
- Executor Framework, Thread Pools — especially tuning them for high-throughput services
CompletableFuture, non-blocking pipelines- Synchronization strategy in multi-tenant applications
Week 2: DSA Is Still Important — But Pattern Recognition Matters More
At the 10-year experience level, Data Structures and Algorithms (DSA)questions don’t just test your coding ability — they test how you think through complex problems under constraints, how you optimize for scale, and how you explain trade-offs clearly and confidently.
Let’s break this down.
Why DSA Still Matters (Even at 10+ Years)
You may be managing teams or making architectural decisions, but DSA remains relevant because:
- Complex systems often break down to data structures at their core.Example: Designing a high-frequency trading system may seem architectural, but under the hood, it could involve priority queues, ring buffers, or lock-free stacks.
- You’re expected to know how to write performant, memory-conscious code. Especially for roles where you’ll own low-latency services or do technical mentorship.
- When hiring managers see poor DSA performance from senior devs, they worry about scalability and engineering depth.
What Interviewers Are REALLY Testing
You won’t be asked to reverse a string or count vowels. They want to understand:
1. How You Think
They want to see how you approach unknown problems and whether you can structure your thinking.
Bad answer: “I’ll try brute force and then optimize.”
Good answer:
“Let’s break this down. The constraints say input size could be 1 million, so I’ll avoid anything worse than O(n log n). My first thought is to use a HashMap for frequency tracking to ensure constant time lookups…”
You’re expected to narrate your thought process, just like you would while mentoring someone or doing a code walkthrough.
2. How You Optimize
Real-world systems don’t have infinite compute or memory. You must show how you’d:
- Trade space for time (or vice versa)
- Reduce memory allocations
- Parallelize tasks when needed
Example Interview Prompt:
“Find the first non-repeating character in a stream of characters.”
Senior-level Thought Process:
- Streaming implies you can’t store everything.
- HashMap + Queue = O(n) solution, but what’s the memory footprint?
- Could use a fixed-size array (since characters are limited) for frequency count → memory efficient
- Maybe debounce processing for bulk throughput instead of per-character read?
Bonus: Show how you’d test the edge cases:
- All characters repeating
- Empty input
- Extremely long input (e.g., logs)
3. How You Explain Trade-Offs
Even if you get to a correct solution, the interviewer wants to know:
- Why didn’t you choose the recursive approach?
- What happens when the input size doubles?
- Is your solution cache-friendly?
- Does it scale on multi-threaded environments?
Example Follow-up:
“You used HashMap here. What if the key space is too large?”
You should explain:
“I’d switch to a Trie or a fixed-size array for known alphabets to avoid unbounded memory growth. If the input is truly unbounded, I’d also consider eviction logic or data streaming techniques.”
What I Focused on in Week 2
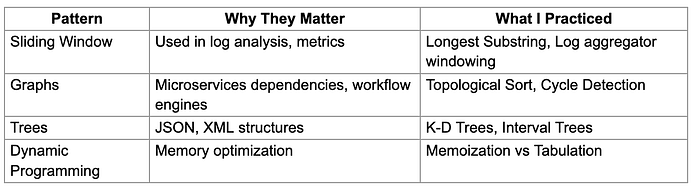
I didn’t try to “grind” problems. I focused on mastering DSA patterns — because patterns help you generalize and solve unseen problems faster.
Here are the ones I prioritized, and why:
Sliding Window Pattern
Why it matters: Used heavily in real-time analytics, rate limiting, log parsers, etc.
Example Problem: Find the longest substring without repeating characters.
Trade-off Analysis:
- Naive = O(n²)
- Optimized = O(n) with HashSet and left/right pointers
- Edge Cases:
- Input:
""(empty) - Input:
"aaaaa"(all same) - Input:
"abcabcbb"(repeating pattern)
Real-world analogy: Rate-limiting user logins in a time window (track using timestamps in queue).
Two Pointers Pattern
Why it matters: Optimizes time and space in sorted data or search problems.
Example Problem: Merge two sorted arrays.
Follow-up:
- In-place?
- What if arrays are linked lists instead of arrays?
- Memory-constrained device?
Production Use: Memory-efficient diff checker between two log streams.
Fast and Slow Pointers (Cycle Detection)
Why it matters: Great for detecting cycles in linked structures (dependency graphs, event flows).
Example: Detect cycle in a linked list.
Follow-up:
- Can you find the start of the cycle?
- Can you do it without modifying the list?
- How would you apply this in real-time systems?
Real-world: Event queue that starts reprocessing old events due to misconfigured pointers.
Hashing Pattern
Why it matters: Used in caching, duplicate detection, distributed systems.
Example Problem: Two Sum (classic)
Variations:
- Find all unique pairs
- Input is unsorted/sorted?
- No extra space allowed?
Production Use: Deduplication of logs/messages before indexing in Elasticsearch.
Recursion and Backtracking
Why it matters: Applies to decision trees, permission trees, dynamic rule engines.
Example: Generate all subsets of a set.
Real-world Application: Feature flag combinations, role-based access generation, test permutations.
Union-Find / Disjoint Sets
Why it matters: Used in social graphs, network partitions, file system sync.
Example Problem: Detect cycles in undirected graphs.
Use-case: Cluster detection in microservice dependencies or chaos engineering.
🧮 Dynamic Programming
Why it matters: Optimizes brute force into usable logic. Applies to pricing engines, ML, cache-heavy services.
Example Problem: Longest Common Subsequence.
Edge cases:
- Very long strings
- Memory constraints (switch to iterative + two-row DP)
📚 How I Practiced
- For each pattern, I picked 2–3 canonical problems
- Solved them in Java, on a whiteboard or Notepad (not always in an IDE)
- For each problem, I forced myself to write:
- The first naive approach
- The optimal approach
- Time/space complexity analysis
- Edge cases
- Real-world use-case
- Spent 15 minutes reading code aloud like in interviews (very effective for verbal clarity)
🧰 Tools I Used
- GeeksforGeeks: Great for Java-based explanations and edge cases
- LeetCode: For high-quality, sorted problems by tag
- Codeforces: For strengthening problem-solving pressure
- Hackerrank’s Interview Prep Kit: Structured, good pacing
- My own notebooks from past interviews
Focused Patterns
Amazon asked: “Design a rate limiter service with O(1) access.” I solved it with a token bucket algorithm + circular array (DSA meets System Design).
Week 3: Spring Boot + Architecture + Production-Grade Design
By week 3, I shifted to what matters most at senior levels:
- How do I solve real-world backend problems?
- What trade-offs do I consider?
- Can I design resilient systems?
Spring Boot (But Think Architecture, Not Annotations)
At this level, they assume you know annotations. What they want:
- Why do we override
WebSecurityConfigurerAdapter? - When to use
@Transactional(propagation=Propagation.REQUIRES_NEW)? - How to inject configurations dynamically with
@RefreshScopeand Spring Cloud Config?
Interview Scenario: Capgemini
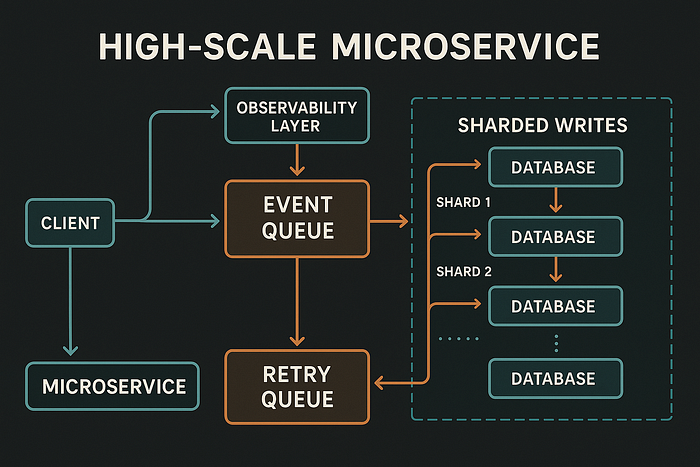
“You have 2M active users. How would you scale your notification service?”
I’d approach this by breaking the problem into functional components, highlighting scalability, latency, throughput, reliability, and observability. The notification service must support multiple channels — like Email, SMS, and Push notifications — and deliver messages in near real-timewith guaranteed delivery, even under load.
Let me walk through how I’d design and scale this system.
1. Decouple Using Event-Driven Architecture
The first principle for scalability is asynchronous communication.
Instead of triggering notifications directly from user actions (e.g., placing an order), I would have the core services publish events like:
OrderPlacedEventPasswordResetRequestedPromotionalCampaignTriggered
These events go to a message brokerlike Kafka (preferred for scale) or RabbitMQ.
This decouples the core business logic from notification logic, allowing us to scale each part independently.
2. Create Dedicated Microservices per Channel
Each notification type (Email, SMS, Push) can have its own microservice:
email-servicesms-servicepush-service
This isolates failure domains. For example, if the SMS gateway goes down, the email system still functions. It also lets us tune each system based on volume and SLA.
Each service would consume messages from Kafka topics, process them, and send via third-party providers like:
- Email: SES, SendGrid
- SMS: Twilio, AWS SNS
- Push: FCM (Firebase Cloud Messaging)
3. Implement Message Queues + DLQs for Resilience
Even with Kafka, I’d use an intermediate internal queue per service, like:
- Kafka → Local processing queue (in-memory or Redis-backed)
This allows:
- Rate limiting per provider (to avoid throttling)
- Retry logic for transient failures
- Dead Letter Queues (DLQ) for failures after
nattempts
I’d implement exponential backoff for retries and alerting on persistent failures using Prometheus + Alertmanager.
4. Horizontal Scalability with Load-Aware Consumers
Each service should be stateless and deployed behind a load balancer (e.g., NGINX, Kubernetes Service). We’d run multiple consumer instances per Kafka topic partition, using Kafka consumer groups to distribute load.
If we receive sudden spikes (say during a flash sale), Kubernetes Horizontal Pod Autoscaler (HPA) can scale pods based on:
- CPU usage
- Queue length
- Lag metrics from Kafka
5. Bulk and Batch Processing
Not all notifications need to be real-time.
For campaign notifications (like marketing emails to all 2M users), I’d:
- Store recipients in batches
- Use a batch job (via Spring Batch or AWS Batch)
- Chunk the messages (e.g., 1K per batch) and push to Kafka in intervals
This prevents traffic bursts and gives room to throttle.
6. Idempotency and De-duplication
For distributed systems, especially with retries, idempotency is critical.
- Every message sent to Kafka should have a unique
messageId - Downstream services store delivery logs (PostgreSQL or NoSQL like Cassandra)
- On retry, check if
messageIdwas already processed
This prevents duplicate notifications from being sent.
7. User Preferences and Delivery Policies
We must also account for:
- Timezone-aware sending (e.g., no SMS at midnight)
- User preferences (opt-in/out)
- Channel fallbacks (if push fails, fallback to SMS)
This data can be cached using Redis to avoid repeated DB hits.
8. Monitoring and Observability
A scalable system is useless if you can’t observe it.
I’d implement:
- Structured logs with correlation IDs (for tracing)
- Metrics like:
- Kafka lag
- Message processing rate
- Delivery success/failure
- SLA violations
- Dashboards: Grafana + Prometheus
- Distributed Tracing: OpenTelemetry or Spring Sleuth + Zipkin
This helps us answer: “Why did this user not get a notification?” within seconds.
9. Geo Distribution and Failover
For a globally distributed user base, I’d deploy services across regions (multi-AZ/multi-region on AWS or GCP) with:
- Global Kafka (or use MirrorMaker 2)
- Edge services close to users (CloudFront, Akamai)
- Circuit breakers and timeouts (via Resilience4j)
Failover strategies must include:
- Auto-fallback to secondary provider (e.g., from Twilio to Plivo)
- Queue spillover to DLQ and alert
10. Security and Compliance
Notifications may carry sensitive info (OTP, account details). So:
- Use TLS for communication
- Encrypt sensitive payloads
- Store minimal logs with redacted content
- Comply with regulations like GDPR, especially for opt-outs and data retention
What I Told the Interviewer
“At 2M active users, reliability, scalability, and observability must be built-in from the start. This isn’t just about sending messages — it’s about respecting user expectations, protecting system health, and being ready to operate under real-world pressure. My design ensures each component scales independently, isolates failures, and can handle both real-time and bulk notifications efficiently.”
This led to a deeper conversation about Kafka tuning, backpressure handling, and scaling producer-consumer flows, which I navigated using specific examples from my production experience.
Ai image
Week 4: System Design + Soft Skills + Hiring Manager Rounds
Most developers with 10 years of experience fail not on tech, but on:
- Communication
- Leadership behavior
- Ownership signals
Managerial Round — TCS
“Tell me about a project where you drove architecture decisions.”
I discussed how I led:
- Migration from Monolith to Microservices for a payment service
- Introduced Circuit Breaker pattern using Resilience4j
- Decoupled services using event sourcing (Kafka)
- Created internal libraries for observability and logging
- Mentored 3 junior devs in CI/CD and Dockerization
TIP: Tie every technical decision to business value. Not “we used Redis,” but “we reduced checkout latency by 40% using Redis as a cache layer.”
Cheat Sheets That Actually Helped (Not Just Fluff)
=> Core Java Mind Map
- JVM Internals
- Threading Models
- Collection Fail-Safe vs Fail-Fast
- GC Tuning Flags
Spring Boot Production Checklist

Real Questions That Made Me Sweat
❓ Amazon (Design + Java)
“Design a distributed logging platform that supports search, alerting, and retries.”
Talked about:
- Kafka for ingestion
- ELK stack (ElasticSearch for search, Kibana for visualization)
- Kafka DLQ for retries
- Backpressure handling
❓ Infosys
“How does Spring handle dependency cycles?”
Explained:
- Constructor injection → cycle breaks
- Setter injection workaround
- Use of
@Lazy,@DependsOn - ApplicationContext lifecycle
❓ Cognizant
“Tell me a time you had to challenge an architectural decision.”
I shared a real story:
- They were using blocking I/O in a high-volume chat app.
- I proposed WebFlux, but the team resisted.
- We A/B tested both. WebFlux saved 60% infra cost.